
In previous posts, we’ve talked about the importance of integrations for clinical diagnostic labs. Integrations can help labs improve business performance, reduce the risk of errors, and boost productivity. We’ve looked at file- and API-based integrations for liquid handlers and how to overcome the technical challenges of implementing integrations within a lab environment. In this post, we’ll take a closer look at the differences between direct and indirect integrations.
Two types of integrations
When you’re integrating clinical laboratory software, you need to choose between two different types of integrations:
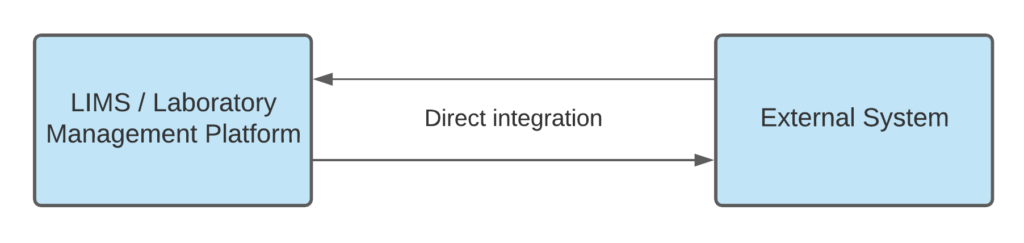
- Direct integration. These integrations often take the form of connecting the API of your LIMS or laboratory management platform to the API of an external system. In some cases, a direct integration may involve invoking a script that uses SQL to update the external system’s database. In other cases, the external system drives the integration. Direct integrations are commonly used for instrument-driven integrations.
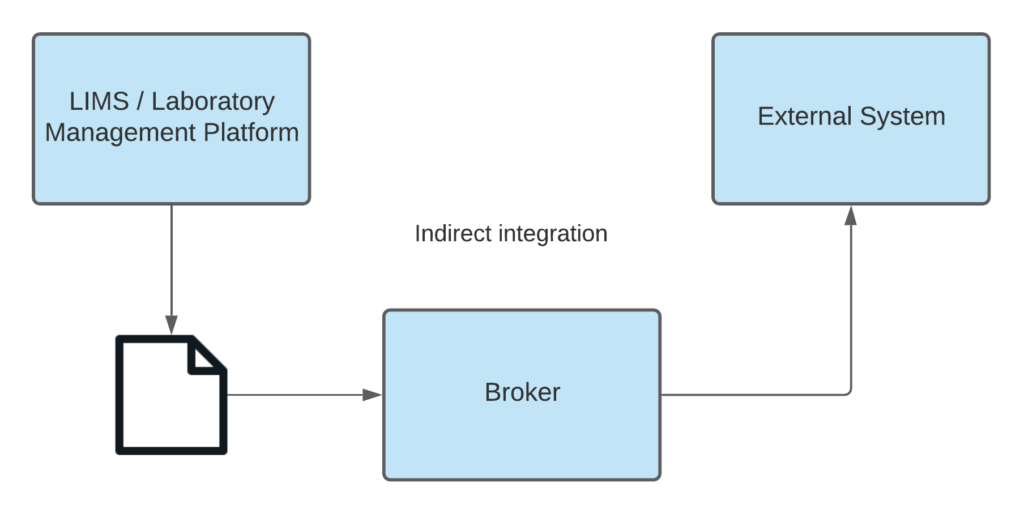
- Indirect integration. These integrations often involve generating a data file from the LIMS. A broker application receives the file, then converts or pushes the data to the external system. Alternatively, the first system could write information to a message bus. The second system subscribes to the message bus and processes the information from there. Conceptually, the same goal is achieved. Indirect integrations can also work in the opposite direction—from the external system to the LIMS—and the data file can be substituted with an HL7 message (often produced by electronic medical records systems). In this case, the broker receives the message, transforms it into XML suitable for use by the LIMS, and updates the LIMS via its API.
Factors to consider when choosing a method
Each of these methods has pros and cons, so we recommend considering the following factors before making a final decision about which type of integration will be the most appropriate.
Data delay
There can be a delay between the data leaving the source system and arriving at the destination system. If real-time updates are critically important, a direct integration could have the advantage, since data is generally transferred in less than a second.
Bi-directional
If you need to exchange data back and forth between systems, you will most likely want to use a direct integration, since this type of integration is almost always two-way. Indirect integrations tend to be one-way and the originating system has no capacity for receiving a response.
Fault tolerance
Indirect integrations are usually more fault-tolerant. For example, imagine a scenario where the destination system is not available. In a direct integration, when the destination system is not available, the source system could block any user action until the data has been transferred. In an indirect integration, this would not be an issue because the broker application monitors data produced by the source system and waits patiently until the destination system becomes available. While this could lead to a significant data delay, that might be tolerable in many cases. For instance, if the LIMS is providing metadata to an accounting system so that invoices can be generated, it’s probably more important that the overall system be fault-tolerant and that correct invoices are generated. A delay in their production likely isn’t significant.
Future-proof
Indirect integrations are better for future-proofing your solution. Imagine you need to update the source or destination system. In a direct integration, you will likely have to redesign, retest, and potentially revalidate the entire integration. Whereas with an indirect integration, even if you replace the source or destination system, half of the integration will still function. In this case, you’ll need to update the broker to understand the new parts of the integration, but this is typically less work than building a new direct integration.
Multiple vendors
When the systems of multiple vendors are involved, indirect integrations are often a better choice. That’s because it’s not common for the source system’s engineers to be familiar with the destination system (and vice versa). An indirect integration has an advantage because source system engineers produce data in a specified format and destination system engineers can contribute to the design of the broker. Both sets of vendors do what they do best—handle incoming and outgoing data to their own systems.
Indirect integrations between systems from multiple vendors also offer advantages for project management. Both halves of the integration can be simulated or tested in isolation, reducing timelines and associated risk.
Error-handling
Error-handling is one of the biggest challenges with indirect integrations. With one-way communication, it can be difficult to discover if there is an error processing the file. Direct integrations with bi-directional communication have an advantage here.
Which type of integration should you choose?
To decide on the most appropriate type of integration for your situation, you need to understand which of the above factors take priority. The following table is a quick guide to which type of integration we think is best for each.
| Considerations | Which type has the advantage |
| Data delay | Direct integration |
| Bi-directional | Direct integration |
| Fault tolerance | Indirect integration |
| Future-proof | Indirect integration |
| Multiple vendors | Indirect integration |
| Error-handling | Direct integration |
Obviously, you’re in the best position to know which of these factors are the most important within your lab environment. However, we’re always happy to talk with you about the specific scenarios you’re facing and help you evaluate the options in light of your priorities. We recognize that every lab is in a unique position, and understand that no one approach will work in every instance.
